Generate Synthetic Test Data for LLM Applications
Manually curating test data can be time-consuming and often causes critical edge cases to be overlooked. With DeepEval's Synthesizer, you can quickly generate thousands of high-quality synthetic goldens in just minutes.
A Golden in DeepEval is similar to an LLMTestCase, but does not require an actual_output and retrieval_context at initialization. Learn more about Goldens in DeepEval here.
This guide will show you how to best utilize the Synthesizer to create synthetic goldens that fit your use case, including:
- Customizing document chunking
- Managing golden complexity through evolutions
- Quality assuring generated synthetic goldens
Key Steps in Data Synthetic Generation
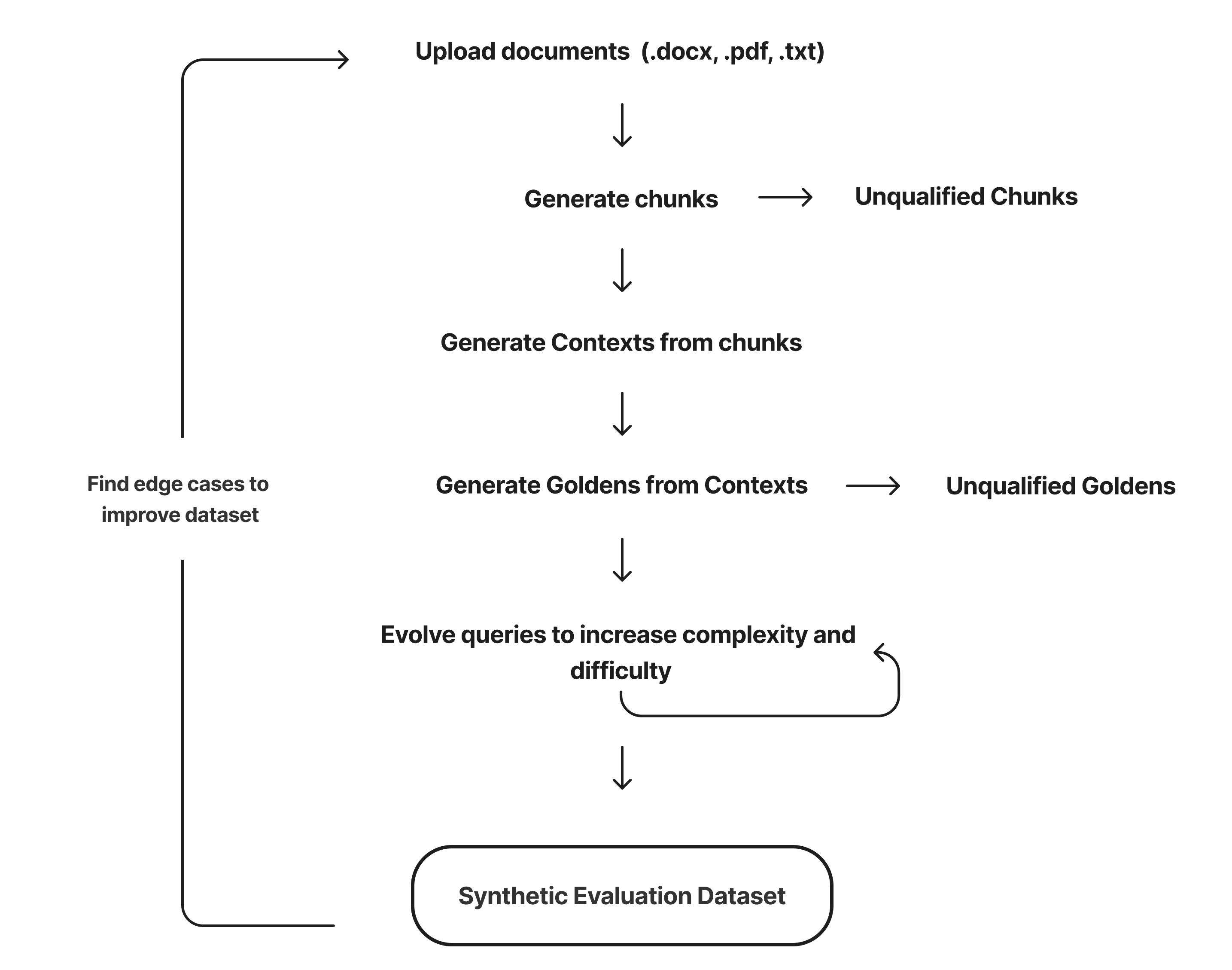
DeepEval leverages your knowledge base to create contexts, from which relevant and accurate synthetic goldens are generated. To begin, simply initialize the Synthesizer and provide a list of document paths that represent your knowledge base:
from deepeval.synthesizer import Synthesizer
synthesizer = Synthesizer()
synthesizer.generate_goldens_from_docs(
document_paths=['example.txt', 'example.docx', 'example.pdf'],
)
The generate_goldens_from_docs function follows several key steps to transform your documents into high-quality goldens:
- Document Loading: Load and process your knowledge base documents for chunking.
- Document Chunking: Split the documents into smaller, manageable chunks
- Context Generation: Group similar chunks (using cosine similarity) to create meaningful
- Golden Generation: Generate synthetic goldens from the created contexts.
- Evolution: Evolve the synthetic goldens to increase complexity and capture edge cases.
Alternatively, if you already have pre-prepared contexts, you can generate goldens directly, skipping the first three steps:
from deepeval.synthesizer import Synthesizer
synthesizer = Synthesizer()
synthesizer.generate_goldens_from_contexts(
contexts=[
["The Earth revolves around the Sun.", "Planets are celestial bodies."],
["Water freezes at 0 degrees Celsius.", "The chemical formula for water is H2O."],
]
)
Document Chunking
In DeepEval, documents are divided into fixed-size chunks, which are then used to generate contexts for your goldens. This chunking process is critical because it directly influences the quality of the contexts, which are used to generated synthetic goldens. You can control this process using the following parameters:
chunk_size: Defines the size of each chunk in tokens. Default is 1024.chunk_overlap: Specifies the number of overlapping tokens between consecutive chunks. Default is 0 (no overlap).max_contexts_per_document: The maximum number of contexts generated per document. Default is 3.
DeepEval uses a token-based splitter, meaning that chunk_size and chunk_overlap are measured in tokens, not characters.
from deepeval.synthesizer import Synthesizer
synthesizer = Synthesizer()
synthesizer.generate_goldens_from_docs(
document_paths=['example.txt', 'example.docx', 'example.pdf'],
chunk_size=1024,
chunk_overlap=0
)
It’s crucial to match the chunk_size and chunk_overlap settings to the characteristics of your knowledge base and the retriever being used. These chunks will form the context for your synthetic goldens, so proper alignment ensures that your generated test cases are reflective of real-world scenarios.
Best Practices for Chunking
- Impact on Retrieval: The chunk size and overlap should ideally align with the settings of the retriever in your LLM pipeline. If your retriever expects smaller or larger chunks for efficient retrieval, adjust the chunking accordingly to prevent mismatch in how context is presented during the golden generation.
- Balance Between Chunk Size and Overlap: For documents with interconnected content, a small overlap (e.g., 50-100 tokens) can ensure that key information isn't cut off between chunks. However, for long-form documents or those with distinct sections, a larger chunk size with minimal overlap might be more efficient.
- Consider Document Structure: If your documents have natural breaks (e.g., chapters, sections, or headings), ensure your chunk size doesn't disrupt those. Customizing chunking for structured documents can improve the quality of the synthetic goldens by preserving context.
If chunk_size is set too large or chunk_overlap too small for shorter documents, the synthesizer may raise an error. This occurs because the document must generate enough chunks to meet the max_contexts_per_document requirement.
To validate your chunking settings, calculate the number of chunks per document using the following formula:
Maximizing Coverage
The maximum number of goldens generated is determined by multiplying max_contexts_per_document by max_goldens_per_context.
It’s generally more efficient to increase max_contexts_per_document to enhance coverage across different sections of your documents, especially when dealing with large datasets or varied knowledge bases. This provides broader insights into your LLM's performance across a wider range of scenarios, which is crucial for thorough testing, particularly if computational resources are limited.
Evolutions
The synthesizer increases the complexity of synthetic data by evolving the input through various methods. Each input can undergo multiple evolutions, which are applied randomly. However, you can control how these evolutions are sampled by adjusting the following parameters:
evolutions: A dictionary specifying the distribution of evolution methods to be used.num_evolutions: The number of evolution steps to apply to each generated input.
Data evolution was originally introduced by the developers of Evol-Instruct and WizardML.. For those interested, here is a great article on how deepeval's synthesizer was built.
from deepeval.synthesizer import Synthesizer
synthesizer = Synthesizer()
synthesizer.generate_goldens_from_docs(
document_paths=['example.txt', 'example.docx', 'example.pdf'],
num_evolutions=3,
evolutions={
Evolution.REASONING: 0.1,
Evolution.MULTICONTEXT: 0.1,
Evolution.CONCRETIZING: 0.1,
Evolution.CONSTRAINED: 0.1,
Evolution.COMPARATIVE: 0.1,
Evolution.HYPOTHETICAL: 0.1,
Evolution.IN_BREADTH: 0.4,
}
)
DeepEval offers 7 types of evolutions: reasoning, multicontext, concretizing, constrained, comparative, hypothetical, and in-breadth evolutions.
- Reasoning: Evolves the input to require multi-step logical thinking.
- Multicontext: Ensures that all relevant information from the context is utilized.
- Concretizing: Makes abstract ideas more concrete and detailed.
- Constrained: Introduces a condition or restriction, testing the model's ability to operate within specific limits.
- Comparative: Requires a response that involves a comparison between options or contexts.
- Hypothetical: Forces the model to consider and respond to a hypothetical scenario.
- In-breadth: Broadens the input to touch on related or adjacent topics.
While the other evolutions increase input complexity and test an LLM's ability to reason and respond to more challenging queries, in-breadth focuses on broadening coverage. Think of in-breadth as horizontal expansion, and the other evolutions as vertical complexity.
Best Practices for Using Evolutions
To maximize the effectiveness of evolutions in your testing process, consider the following best practices:
Align Evolutions with Testing Goals: Choose evolutions based on what you're trying to evaluate. For reasoning or logic tests, prioritize evolutions like Reasoning and Comparative. For broader domain testing, increase the use of In-breadth evolutions.
Balance Complexity and Coverage: Use a mix of vertical complexity (e.g., Reasoning, Constrained) and horizontal expansion (e.g., In-breadth) to ensure a comprehensive evaluation of both deep reasoning and a broad range of topics.
Start Small, Then Scale: Begin with a smaller number of evolution steps (
num_evolutions) and gradually increase complexity. This helps you control the challenge level without generating overly complex goldens.Target Edge Cases for Stress Testing: To uncover edge cases, increase the use of Constrained and Hypothetical evolutions. These evolutions are ideal for testing your model under restrictive or unusual conditions.
Monitor Evolution Distribution: Regularly check the distribution of evolutions to avoid overloading test data with any single type. Maintain a balanced distribution unless you're focusing on a specific evaluation area.
Accessing Evolutions
You can access evolutions either from the DataFrame generated by the synthesizer or directly from the metadata of each golden:
from deepeval.synthesizer import Synthesizer
# Generate goldens from documents
goldens = synthesizer.generate_goldens_from_docs(
...
)
# Access evolutions through the DataFrame
goldens_dataframe = synthesizer.to_pandas()
goldens_dataframe.head()
# Access evolutions directly from a specific golden
goldens[0].additional_metadata["evolutions"]
Qualifying Synthetic Goldens
Generating synthetic goldens can introduce noise, so it's essential to qualify and filter out low-quality goldens from the final dataset. Qualification occurs at three key stages in the synthesis process.
Context Filtering
The first two qualification steps happen during context generation. Each chunk is randomly sampled for each context and scored based on the following criteria:
- Clarity: How clear and understandable the information is.
- Depth: The level of detail and insight provided.
- Structure: How well-organized and logical the content is.
- Relevance: How closely the content relates to the main topic.
Scores range from 0 to 1. To pass, a chunk must achieve an average score of at least 0.5. A maximum of 3 retries is allowed for each chunk if it initially fails.
Additional chunks are sampled using a cosine similarity threshold of 0.5 to form the final context, ensuring that only high-quality chunks are included in the context.
Synthetic Input Filtering
In the next stage, synthetic inputs are generated from the goldens. These inputs are evaluated and scored based on:
- Self-containment: The query is understandable and complete without needing additional external context or references.
- Clarity: The query clearly conveys its intent, specifying the requested information or action without ambiguity.
Similar to context filtering, these inputs are scored on a scale of 0 to 1, with a minimum passing threshold. Each input is allowed up to 3 retries if it doesn't meet the quality criteria.
Accessing Quality Scores
You can access the quality scores from the synthesized goldens using the DataFrame or directly from each golden.
from deepeval.synthesizer import Synthesizer
# Generate goldens from documents
goldens = synthesizer.generate_goldens_from_docs(
...
)
# Access quality scores through the DataFrame
goldens_dataframe = synthesizer.to_pandas()
goldens_dataframe.head()
# Access quality scores directly from a specific golden
goldens[0].additional_metadata["synthetic_input_quality"]
goldens[0].additional_metadata["context_quality"]