LLM Application Monitoring in Production
Quick Summary
deepeval allows you to live monitor LLM responses in production, which you can enable real-time evaluations on. By monitoring responses, you can leverage our hosted evaluation infrastructure to identify unsatisfactory LLM responses, have human annotators send feedback to such responses, and improve your evaluation dataset over time.
Monitoring Live Responses
To monitor LLM responses, use the deepeval.track(...) method in your LLM application to start tracking responses.
import deepeval
# At the end of your LLM call,
# usually in your backend API handler
deepeval.track(
event_name="Chatbot",
model="gpt-4",
input="input",
response="response"
)
There are four mandatory and ten optional parameters when using the track() function to monitor responses in production:
event_name: typestrspecifying the type of event tracked.model: typestrspecifying the name of the LLM model used.input: typestr.response: typestr.- [Optional]
retrieval_context: typelist[str]that indicates the context that were retrieved in your RAG pipeline. - [Optional]
additional_data: typedict[str, Union[str, dict, Link]]. See below for further details. - [Optional]
hyperparameters: typedict[str, Union[str, int, float]]. You can provide a dictionary to specify any additional hyperparamters used to generate the response. - [Optional]
distinct_id: typestrto identify end users using your LLM application. - [Optional]
conversation_id: typestrto group together multiple messages under a single conversation thread. - [Optional]
completion_time: typefloatthat indicates how many seconds it took your LLM application to complete. - [Optional]
token_usage: typefloat - [Optional]
token_cost: typefloat - [Optional]
fail_silently: typebool. You should set this toFalsein development to check if tracking is working properly. Defaulted toFalse. - [Optional]
raise_expection: typebool. You should set this toFalsein production if you don't want to raise expections in production. Defaulted toTrue.
Please do NOT provide placeholder values for optional parameters. Leave it blank instead.
The track() function returns an event_id upon a successful API request to Confident's servers, which you can later use to send human feedback regarding a particular LLM response you've tracked.
import deepeval
event_id = deepeval.track(...)
Congratulations! With a few lines of code, deepeval will now automatically log all LLM responses in production to Confident AI.
Tracking Custom Hyperparameters
In addition to tracking which model was used to generate each response, you can also associate any custom hyperparameters you wish to each response you're tracking.
import deepeval
deepeval.track(
...
model="gpt-4",
hyperparameters={
"prompt template": "...",
"temperature": 1,
"chunk size": 500
}
)
Logging hyperparameters allows you to more easily filter and search for different responses on Confident AI.
Tracking Additional Custom Data
Similar to hyperparameters, you can easily associate custom additional data for each response.
import deepeval
from deepeval.events.api import Link
deepeval.track(
...
additional_data={
"Example Text": "...",
# the Link class allows you to access the link directly on Confident AI
"Example Link": Link(value="https://www.youtube.com"),
"Example list of Links": [Link(value="https://www.instagram.com")],
"Example JSON": {"Any Key": "Any Value"}
},
)
Note that you can log either text, a Link, list of Links, or any custom dict (as shown in the "Example Json"). Similar to hyperparameter, you can also filter and search for different responses based on the provided custom data.
Although you can technically log a link as a native string, the Link(value="...") class allows you to access said link directly on Confident AI. You should also aim to have your Links start with 'https://...'.
Sending Human Feedback
deepeval allows you to send human feedback for a particular LLM response by specifying an event_id returned through the track() function.
There are two types of feedback:
- User provided feedback. A user feedback, is feedback provided by your end users. If you're building a discord bot for example, this will likely be the users interacting with your discord bot on a daily basis.
- Reviewer provided feedback. A reviewer feedback, is feedback provided by your LLM quality assurance personnel, whoever they might be. These might be data annotators and labellers, or even domain experts that checking the quality of LLM responses in production.
Using the event_id returned from track(), here's how you can send feedback to Confident:
import deepeval
event_id = deepeval.track(...)
deepeval.send_feedback(
event_id=event_id,
provider="user",
rating=6,
explanation="...",
expected_response="..."
)
There are three mandatory and four optional parameters when using the send_feedback() function:
event_id: a string representing theevent_idreturned from thedeepeval.track()function.provider: a string of either"user"OR"reviewer"to specify the type of feedback provider.rating: an integer ranging from 1 - 5, inclusive.- [Optional]
explanation: a string that serves as the explanation for the given rating. - [Optional]
expected_response: a string representing what the ideal response is. - [Optional]
fail_silently: a boolean which when set toTruewill neither print nor raise any exceptions on error. Defaulted toFalse. - [Optional]
raise_expection: a boolean which when set toTruewill not raise any expections on error. Defaulted toTrue.
Responses on Confident AI
Confident offers an observatory to view responses and identify ones where you want to augment your evaluation dataset with.
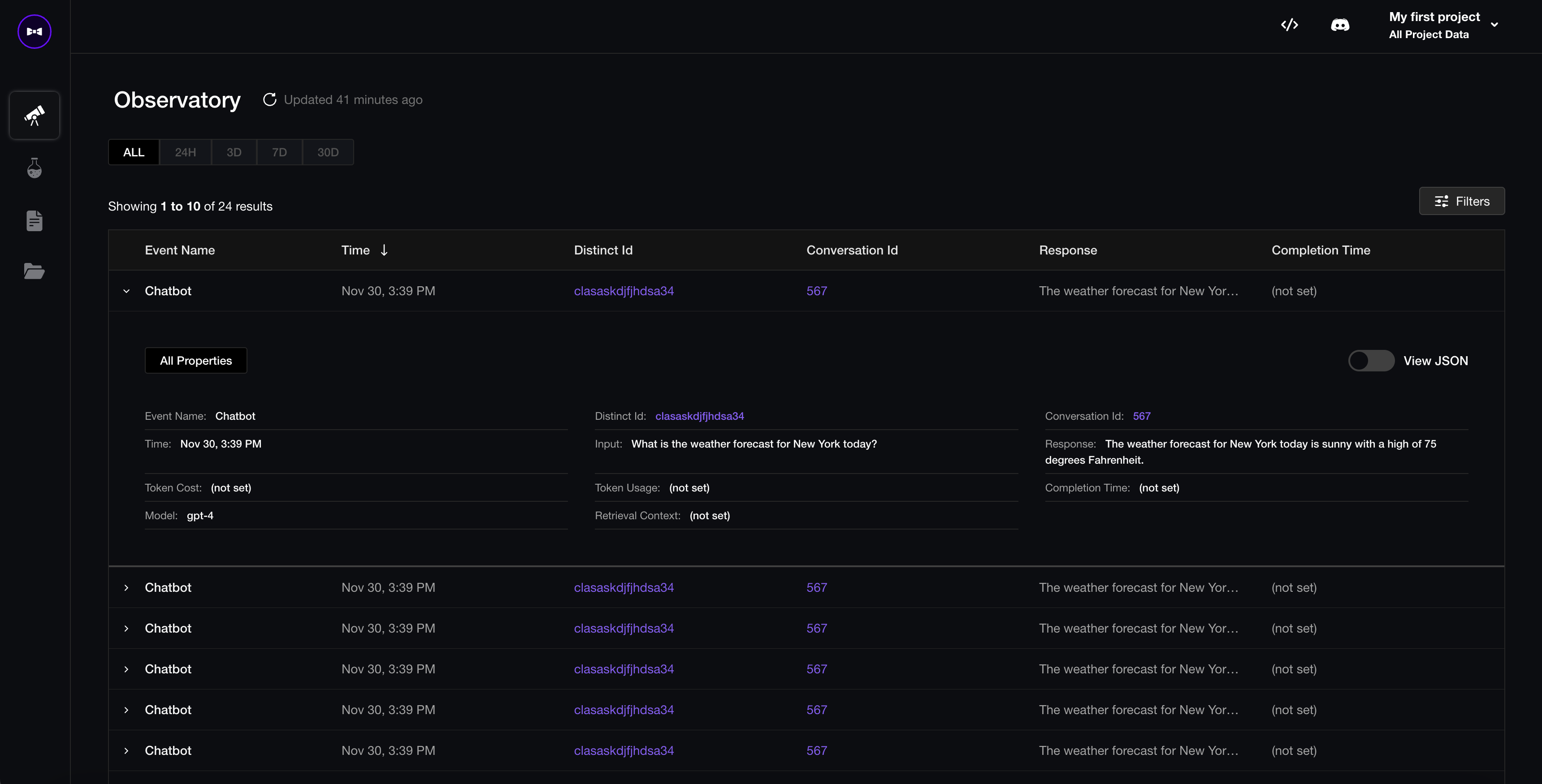
If you're building an LLM chatbot, you can also view entire conversation threads via the conversation_id.

Enable Real-Time Evals
To monitor how your LLM application is performing over time, and be alerted of any unsatisfactory LLM responses in production, head to the "projects details" section via the left navigation drawer to turn on the metrics you wish to enable in production. Confident AI will automatically run evaluations for enabled metrics for all incoming events.
