Qdrant
Quick Summary
Qdrant is a vector database and vector similarity search engine that is optimized for fast retrieval. It was written in rust, achieves 3ms response for 1M Open AI Embeddings, and comes with built-in memory compression.
You can easily get started with Qdrant in python by running the following command in your CLI:
pip install qdrant-client
With DeepEval, you can evaluate your Qdrant retriever and optimize for performance in addition to speed, by configuring hyperparameters in your Qdrant retrieval pipeline such as vector dimensionality, distance (or similarity function), embedding model, limit (or top-K), among many others.
To learn more about Qdrant, visit their documentation.
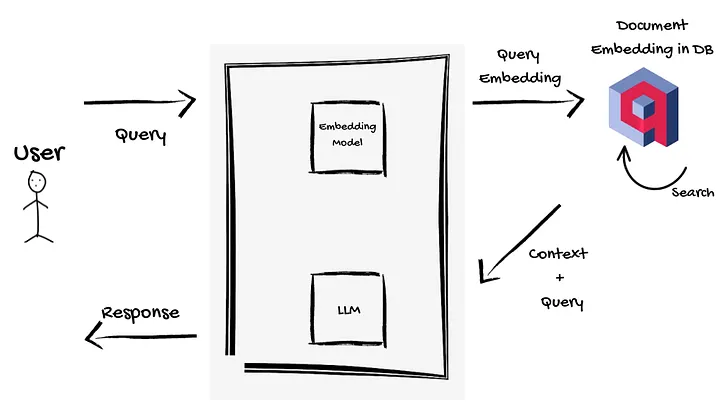
This diagram demonstrates how the Qdrant retriever integrates with an external embedding model and an LLM generator to enhance your RAG pipeline.
Setup Qdrant
To get started with Qdrant, first create a Python QdrantClient to connect to your local or cloud-hosted Qdrant instance by providing the corresponding URL.
import qdrant_client
import os
client = qdrant_client.QdrantClient(
url="http://localhost:6333" # Change this if using Qdrant Cloud
)
Next, create a Qdrant collection with the appropriate vector configurations. This collection will store your document embeddings as vectors and the corresponding text chunks as metadata. In the code snippet below, we set the distance function to cosine similarity and define a vector dimension of 384.
You'll want to iterate and test different values for hyperparameters like size and distance if you don't achieve satisfying scores during evaluation.
...
# Define collection name
collection_name = "documents"
# Create collection if it doesn't exist
if collection_name not in [col.name for col in client.get_collections().collections]:
client.create_collection(
collection_name=collection_name,
vectors_config=qdrant_client.http.models.VectorParams(
size=384, # Vector dimensionality
distance="cosine" # Similarity function
),
)
To add documents to your Qdrant collection, first embed the chunks before upserting them using the PointStruct structure. In this example, we'll use all-MiniLM-L6-v2 from sentence_transformers as our embedding model.
# Load an embedding model
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
# Example document chunks
document_chunks = [
"Qdrant is a vector database optimized for fast similarity search.",
"It uses HNSW for efficient high-dimensional vector indexing.",
"Qdrant supports disk-based storage for handling large datasets.",
...
]
# Store chunks with embeddings
for i, chunk in enumerate(document_chunks):
embedding = model.encode(chunk).tolist() # Convert text to vector
client.upsert(
collection_name=collection_name,
points=[
qdrant_client.http.models.PointStruct(
id=i, vector=embedding, payload={"text": chunk}
)
]
)
We'll use this Qdrant collection in the following sections as our retrieval engine to retrieve contexts using cosine similarity for response generation. The retrieved contexts will be passed to our LLM generator, which will generate the final response in our RAG pipeline.
Evaluating Qdrant Retrieval
To evaluate your Qdrant retriever, you'll first need to prepare an LLMTestCase, which includes an input, actual_output, expected_output, and retrieval_context. This requires defining an input and expected_output before generating a response and extracting the retrieval contexts.
In this example, we'll be using the following input:
"How does Qdrant work?"
and the corresponding expected output:
"Qdrant performs fast and scalable vector search using HNSW indexing and disk-based storage."
Preparing your Test Case
To generate the response or actual_output from your RAG pipeline, you'll first need to retrieve relevant contexts from your Qdrant collection. To achieve this, we'll define a search function that embeds the input using the same embedding model (all-MiniLM-L6-v2) as above, then search for the top 3 most similar vectors and extract the corresponding texts.
...
def search(query, top_k=3):
query_embedding = model.encode(query).tolist()
search_results = client.search(
collection_name=collection_name,
query_vector=query_embedding,
limit=top_k # Retrieve the top K most similar results
)
return [hit.payload["text"] for hit in search_results] if search_results else None
query = "How does Qdrant work?"
retrieval_context = search(query)
We'll then insert these contexts into our prompt template to provide additional context and help ground the response.
...
prompt = """
Answer the user question based on the supporting context
User Question:
{input}
Supporting Context:
{retrieval_context}
"""
actual_output = generate(prompt) # hypothetical function, replace with your own LLM
print(actual_output)
We'll then pass the input and expected output that was initially defined into an LLMTestCase, along with the actual output and retrieval context that we generated and searched for.
from deepeval.test_case import LLMTestCase
...
test_case = LLMTestCase(
input=input,
actual_output=actual_output,
retrieval_context=retrieval_context,
expected_output="Qdrant is a powerful vector database optimized for semantic search and retrieval.",
)
Before proceeding with evaluations, let's examine the actual_output that was generated:
Qdrant is a scalable vector database optimized for high-performance retrieval.
Running Evaluations
To evaluate your Qdrant retriever engine, define the selection of metrics you wish to evaluate your retriever on, before passing the metrics and test case into the evaluate function.
Unless you have custom evaluation criteria, it's best to evaluate your test case using ContextualRecallMetric, ContextualPrecisionMetric, and ContextualRelevancyMetric, as these metrics assess the effectiveness of your retriever. You can learn more about RAG metrics here
from deepeval.metrics import (
ContextualRecallMetric,
ContextualPrecisionMetric,
ContextualRelevancyMetric,
)
...
contextual_recall = ContextualRecallMetric(),
contextual_precision = ContextualPrecisionMetric()
contextual_relevancy = ontextualRelevancyMetric()
evaluate(
[test_case],
metrics=[contextual_recall, contextual_precision, contextual_relevancy]
)
Improving Qdrant Retrieval
Let's say that after running multiple test cases, we observed that the Contextual Precision score is lower than expected. This suggests that while our retriever is fetching relevant contexts, some of them might not be the best match for the query, leading to noise in the response.
Key Findings
| Query | Contextual Precision Score | Contextual Recall Score |
|---|---|---|
| "How does Qdrant store vector data?" | 0.39 | 0.92 |
| "Explain Qdrant's indexing method." | 0.35 | 0.89 |
| "What makes Qdrant efficient for retrieval?" | 0.42 | 0.83 |
Addressing Low Precision
Since precision evaluates how well the retrieved contexts match the query, a lower score often indicates that some retrieved results are not as semantically relevant as they should be. Possible solutions include:
Using a More Domain-Specific Embedding Model
If your use case involves technical documentation, a general-purpose model likeall-MiniLM-L6-v2might not be the best fit. Consider testing models such as:BAAI/bge-small-enfor better retrieval ranking.sentence-transformers/msmarco-distilbert-base-v4for dense passage retrieval.nomic-ai/nomic-embed-text-v1for long-form document retrieval.
Adjusting Vector Dimensions
If switching models, ensure that the vector dimensions in Qdrant match the embedding output to avoid misalignment.Filtering Less Relevant Results
Applying metadata filters can help exclude unrelated chunks that might be skewing precision.
Next Steps
Once you've tested alternative embedding models or other altnerate hyperparameters, you'll want to generate new test cases and re-evaluate retrieval quality to measure improvements. Keep an eye on Contextual Precision, as an increase indicates more focused and relevant context retrieval.
For deeper insights into retrieval performance and to compare embedding model variations, consider tracking your evaluations in Confident AI.